Looking for a new opportunity as DevOps engineer
I am currently seeking a new opportunity as a DevOps Engineer, available from February 2026. I am open to remote or hybrid work from Prague, Czechia (Europe), for a long-term, full-time position or B2B contract - 300 EUR / daily. Please feel free to contact me for further details. You can also review my professional background on my LinkedIn profile.
Automating Post-Incident Reports with Claude
Post-incident reports (PIRs) are one of those tasks that everybody agrees are valuable and nobody enjoys writing. After a long incident, the last thing an on-call engineer wants to do is reconstruct a timeline from Slack threads, runbooks, and half-remembered decisions at 2 AM.
This tutorial walks through the exact Python pipeline I built at DHL IT Services that reduced PIR drafting from 2–3 hours to a 15-minute review cycle.
How the pipeline works#
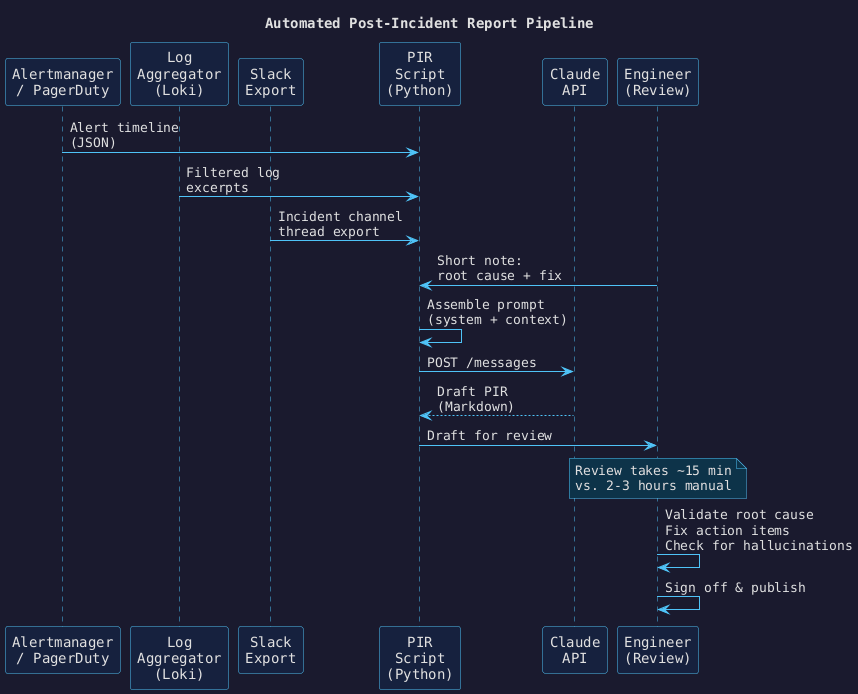
The inputs are assembled from four sources, combined into a single prompt, and sent to Claude. The output is a structured Markdown draft ready for human review and sign-off.
Prerequisites#
pip install anthropic python-dotenv
# .env
ANTHROPIC_API_KEY=sk-ant-...
Step 1 — Define the system prompt#
This is the most important part. The system prompt specifies the exact output structure and the rules Claude must follow. Vague prompts produce vague reports.
SYSTEM_PROMPT = """
You are a senior site reliability engineer writing a post-incident report.
Structure the report with EXACTLY these sections and headings:
## Summary
2-3 sentences. What happened, what was the customer impact, how long did it last.
## Timeline
Bullet list. UTC timestamps. Factual only — no interpretation.
Use passive voice to avoid blame language.
Example: "14:23 UTC — Alert fired for error rate > 5% on payments-api."
## Root Cause
One concise paragraph. What was the underlying technical cause.
## Contributing Factors
Bullet list. Conditions that allowed the root cause to have the impact it did.
## Action Items
Bullet list. Each item: [OWNER] Description (due: YYYY-MM-DD placeholder).
Rules:
- Do not speculate. If information is missing, write [UNKNOWN].
- Do not assign blame to individuals.
- Do not include information not present in the provided context.
"""
Step 2 — Collect and assemble the inputs#
import json
from pathlib import Path
def assemble_context(
alert_json_path: str,
log_excerpt_path: str,
slack_export_path: str,
engineer_note: str,
) -> str:
alert_data = json.loads(Path(alert_json_path).read_text())
logs = Path(log_excerpt_path).read_text()
slack = Path(slack_export_path).read_text()
return f"""
## Alert Timeline (from Alertmanager)
```json
{json.dumps(alert_data, indent=2)}
Log Excerpts (filtered by incident time window)#
{logs}
Slack Incident Channel Thread#
{slack}
Engineer Note (root cause + remediation)#
{engineer_note} """
The `engineer_note` is the only human input required after the incident — a 2–3 sentence description
of what the root cause turned out to be and how it was fixed. Everything else is pulled automatically.
---
## Step 3 — Call Claude and write the draft
```python
import anthropic
import os
from datetime import datetime
client = anthropic.Anthropic(api_key=os.environ["ANTHROPIC_API_KEY"])
def generate_pir(context: str, incident_id: str) -> str:
response = client.messages.create(
model="claude-opus-4-6",
max_tokens=2048,
system=SYSTEM_PROMPT,
messages=[
{
"role": "user",
"content": f"Please write a post-incident report for the following incident data:\n\n{context}",
}
],
)
draft = response.content[0].text
output_path = Path(f"pirs/{incident_id}-draft.md")
output_path.parent.mkdir(exist_ok=True)
output_path.write_text(draft)
print(f"Draft written to {output_path}")
return draft
Step 4 — Run the pipeline#
if __name__ == "__main__":
incident_id = "INC-2025-0622"
engineer_note = (
"Root cause was an OOMKill on the payments-api pods due to a memory limit "
"set too low (128Mi). A recent code change introduced a memory leak in the "
"connection pool. Fixed by raising the limit to 256Mi and deploying the fix "
"for the connection pool bug."
)
context = assemble_context(
alert_json_path="data/alertmanager-INC-2025-0622.json",
log_excerpt_path="data/logs-INC-2025-0622.txt",
slack_export_path="data/slack-INC-2025-0622.txt",
engineer_note=engineer_note,
)
generate_pir(context, incident_id)
Example output (excerpt)#
## Summary
On 2025-06-22 between 14:19 and 16:04 UTC, the payments-api service experienced
repeated CrashLoopBackOff restarts due to container OOMKills, resulting in elevated
error rates and degraded checkout functionality for approximately 18% of users.
The incident lasted 1 hour 45 minutes.
## Timeline
- 14:19 UTC — Error rate alert fired for payments-api (threshold: 5%, observed: 23%)
- 14:23 UTC — On-call engineer paged via PagerDuty
- 14:31 UTC — CrashLoopBackOff confirmed on 2/3 pods in prod namespace
- 14:45 UTC — OOMKill identified in pod events
- 15:12 UTC — Memory limit raised to 256Mi, rolling restart initiated
- 15:28 UTC — All pods healthy, error rate returned to baseline
- 16:04 UTC — Monitoring confirmed stable, incident closed
## Root Cause
A memory leak introduced in the connection pool module caused payments-api containers
to exceed their 128Mi memory limit, triggering repeated OOMKills.
What Claude does well here#
- Synthesising a coherent timeline from noisy, overlapping sources (Slack + logs + alerts).
- Producing consistently structured output that matches the template every time.
- Identifying contributing factors that an exhausted engineer might overlook.
What still requires a human#
- Validating the root cause against actual code or config changes.
- Catching hallucinations — Claude occasionally invents a plausible-sounding timestamp or service name not present in the source data. Always diff the output against your raw inputs.
- Deciding action item priority — which items are worth tracking versus which are nice-to-haves.
The review step is not optional. But reviewing a well-structured 15-page draft is fundamentally different from writing one from scratch at the end of a two-hour incident.
Looking for a new opportunity as DevOps engineer
I am currently seeking a new opportunity as a DevOps Engineer, available from February 2026. I am open to remote or hybrid work from Prague, Czechia (Europe), for a long-term, full-time position or B2B contract - 300 EUR / daily. Please feel free to contact me for further details. You can also review my professional background on my LinkedIn profile.